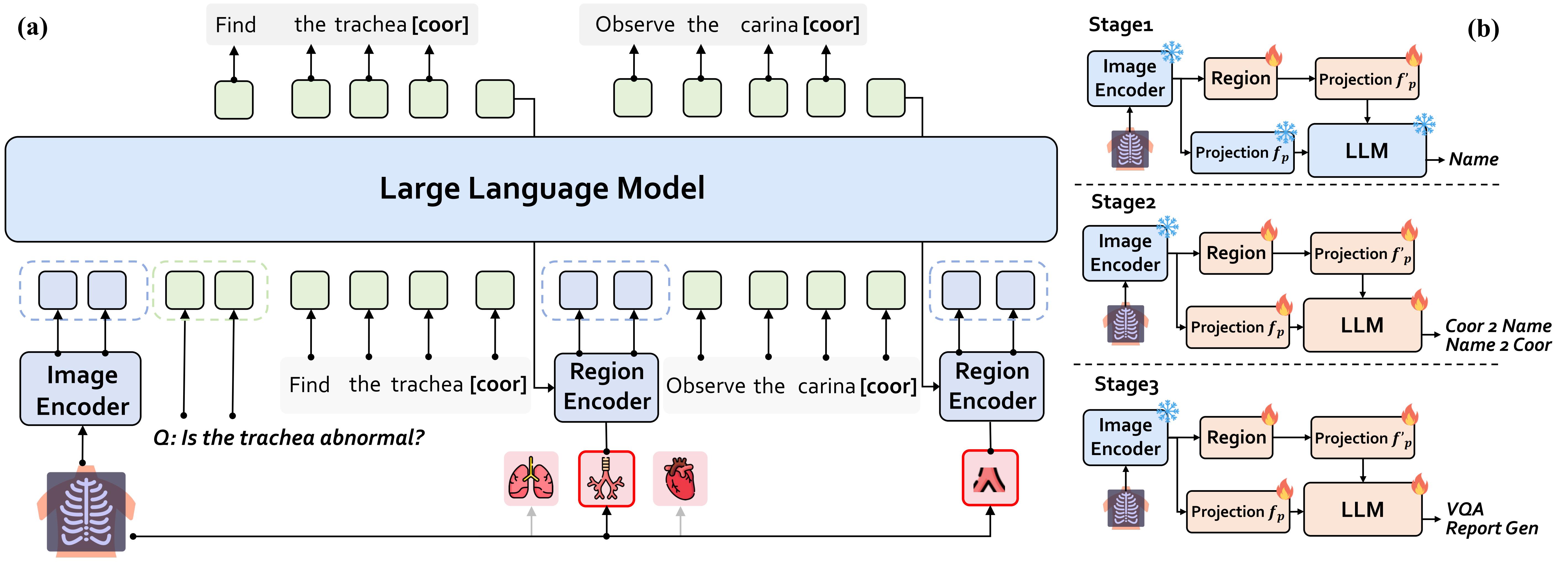
Chest X-rays (CXRs) are the most frequently performed imaging
examinations in clinical settings. Recent advancements in Large
Multimodal Models (LMMs) have enabled automated CXR
interpretation, enhancing diagnostic accuracy and efficiency.
However, despite their strong visual understanding, current
Medical LMMs (MLMMs) still face two major challenges: (1)
Insufficient regionlevel understanding and interaction, and (2)
Limited accuracy and interpretability due to singlestep
reasoning. In this paper, we empower MLMMs with anatomycentric
reasoning capabilities to enhance their interactivity and
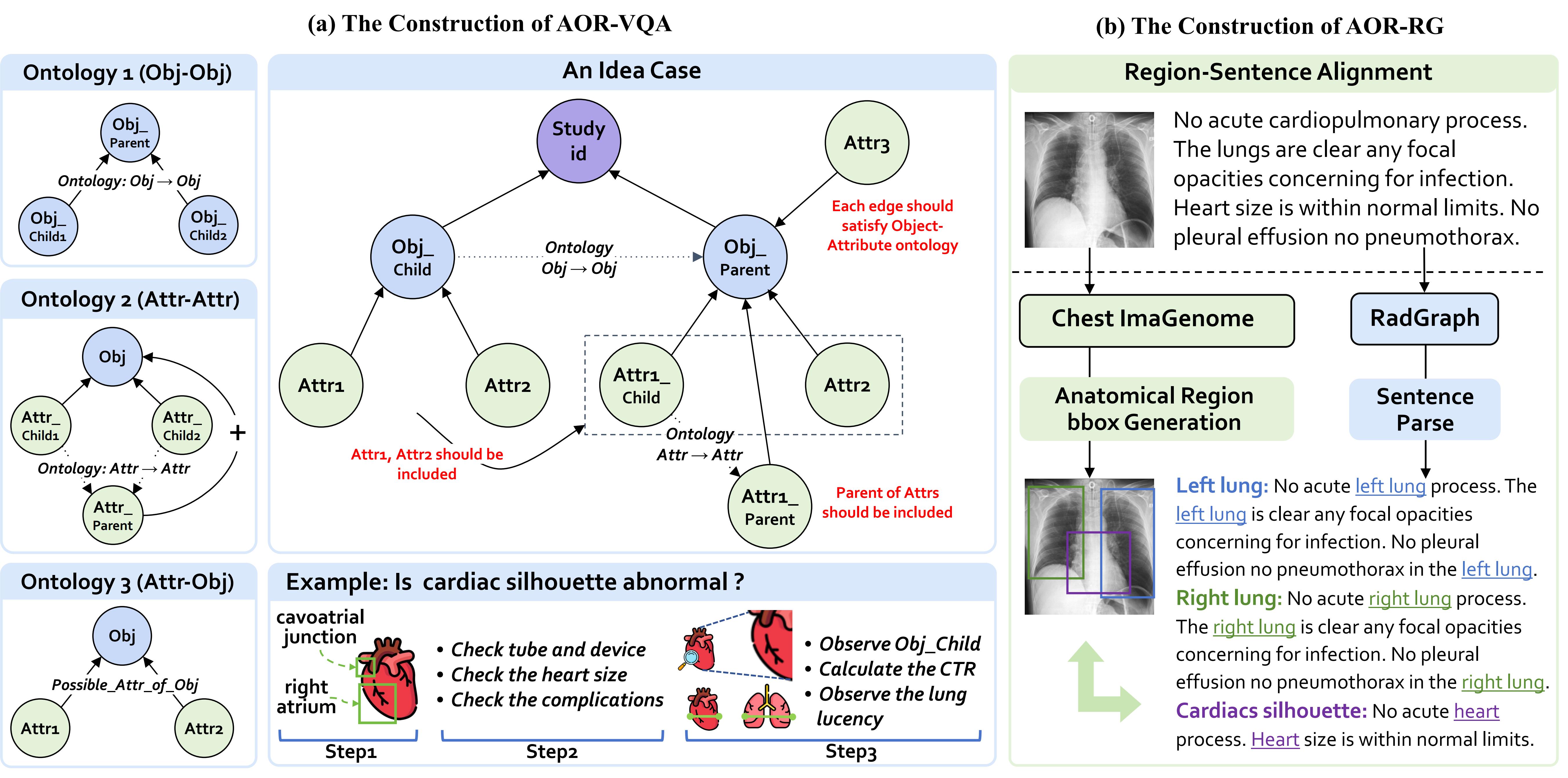
explainability. Specifically, we first propose an Anatomical
Ontology-Guided Reasoning (AOR) framework, which centers on
cross-modal region-level information to facilitate multi-step
reasoning. Next, under the guidance of expert physicians, we
develop AOR-Instruction, a large instruction dataset for MLMMs
training. Our experiments demonstrate AOR's superior performance
in both VQA and report generation tasks.